
Anthropic推出首个“混合”推理模型, 编程能力再度提升
北京时间2月25日凌晨,人工智能初创公司Anthropic正式发布Claude 3.7 Sonnet模型,新增了推理能力以及更强大的编程能力。目前,Claude 3.7 Sonnet已经全面上线,所有用户都可以体验,但是免费用户没有机会体验最新模型的“扩展思维”功能。
首个“混合”推理模型
Anthropic为Claude 3.7 Sonnet模型贴了一个标签:市场上的首个“混合”推理模型。
所谓“混合”是指,模型同时具备“推理模式”(一步一步推理)与传统模式(即时生成答案)的能力。
目前多数模型厂商推出了独立的推理模型,比如 OpenAI 推出了o1、o3系列模型。但Anthropic的理念不太一样。

“正如人类使用单个大脑进行快速反应和深度思考一样,”Anthropic解释称,“我们认为推理应该是前沿模型的综合能力,而不是完全独立的模型。”
因此,Claude 3.7 Sonnet 在多个方面体现了这一理念。比如:Claude 3.7 Sonnet 既是普通的大语言模型,又是推理模型:用户可以选择何时让模型正常回答,何时让模型在回答前思考更长时间。
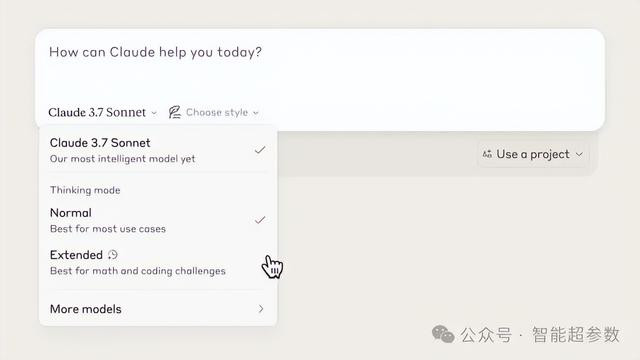
在标准模式下,Claude 3.7 Sonnet是Claude 3.5 Sonnet的升级版。在扩展思维模式下,它会在回答前进行自我反思,从而提高其在数学、物理、遵循指令、编码和许多其他任务上的表现。
由于“扩展思维”模式需要耗费较多算力,容易推高成本,Anthropic 表示,API 用户还可以对模型的思考预算进行细粒度控制,也即时控制推理所消耗的tokens 数量。
目前,在标准和扩展思维模式下,Claude 3.7 Sonnet的价格与其前代产品相同,每百万输入 tokens 3美元,每百万输出 tokens 15美元(其中包括思考 tokens)。
编程能力再次增强
新发布的Claude 3.7 Sonnet模型除了加上了推理能力外,在编码和前端 Web 开发方面表现出了特别显著的改进。
Cursor、Cognition、Vercel、Replit等多个编程助手也对Claude的编码能力给予了高度评价。其中,Cursor指出,“Claude在实际编码任务中再次名列前茅,在处理复杂代码库和高级工具使用等领域都有显著改进”。
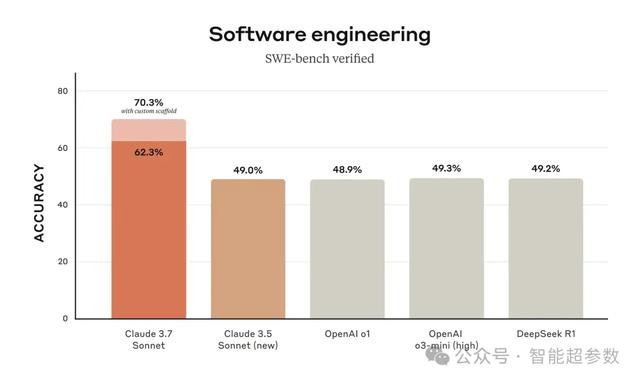
Claude 3.7 Sonnet 在 SWE-bench Verified上取得了一流的性能,以70.3%的优异成绩刷新新纪录。该测试评估了AI模型解决实际软件问题的能力。
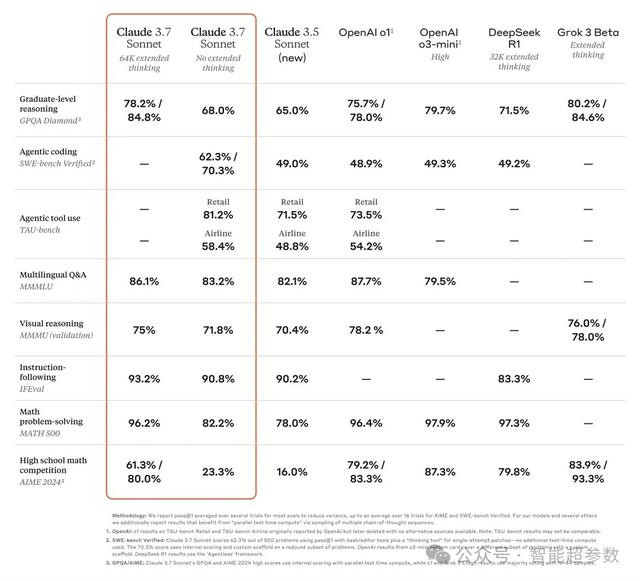
此外,Claude 3.7 Sonnet在指令遵循、一般推理、多模态能力和代理编码方面表现出色,扩展思维在数学和科学方面提供了显著的提升。
这次Anthropic 还发布了自研的第一款代理编码工具Claude Code,它使开发人员能够直接从他们的终端将大量工程任务委托给Claude。
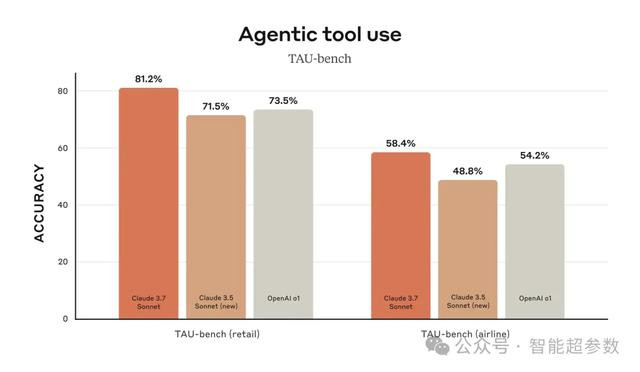
此外,Claude 3.7 Sonnet在TAU-bench上实现了最先进的性能,TAU-bench是一个框架,用于测试AI Agent在复杂的现实任务中与用户和工具 的交互能力。

Anthropic指出,Claude 3.7 Sonnet和Claude Code标志着人工智能系统迈出了重要一步,这些系统可以真正增强人类的能力。凭借其深度推理、自主工作和有效协作的能力,它们使我们更接近人工智能丰富和扩展人类能力的未来。
目前Claude 3.7 Sonnet混合推理基础模型已经正式登陆Amazon Bedrock。并且该模型已集成至基于Amazon Bedrock构建的Amazon Q开发者工具。开发者可通过Q工具智能调用Claude 3.7 Sonnet等模型,提升软件开发全生命周期效率。
同时也有报道称,Anthropic即将完成一轮35亿美元的融资,投后估值615亿美元,最新一轮融资的投资者包括风投公司Lightspeed Venture Partners、General Catalyst和Bessemer Venture Partners等。亚马逊也计划在2025年第四季度再向Anthropic投资27亿美元。